-
프로그래밍 패러다임Computer Science 2023. 3. 12. 20:25

목차
- 선언형과 함수형 프로그래밍
- 순수함수
- 고차함수
- 일급 객체
- 객체지향 프로그래밍
- 추상화
- 캡슐화
- 상속성
- 다형성
- 오버로딩
- 오버라이딩
- OOP 설계 원칙
- 단일 책임 원칙
- 개방-폐쇄 원칙
- 리스코프 치환 원칙
- 인터페이스 분리 원칙
- 의존 역전 원칙
- 절차지향형 프로그래밍
프로그래밍 패러다임(programming paradigm)은 프로그래머에게 프로그래밍의 관점을 갖게 해주는 역할을 하는 개발 방법론입니다.
예를 들어 객체지향 프로그래밍은 프로그래머들이 프로그램을 상호 작용하는 객체들의 집합으로 볼 수 있게 하는 반면에, 함수형 프로그래밍은 상태 값을 지니지 않는 함숫값들의 연속으로 생각할 수 있게 해 줍니다.
프로그래밍 패러다임은 크게 선언형, 명령형으로 나누며, 선언형은 함수형이라는 하위 집합을 갖습니다. 또한, 명령형은 다시 객체지향, 절차지향으로 나눕니다.
프로그래밍 패러다임에 대한 이미지입니다.
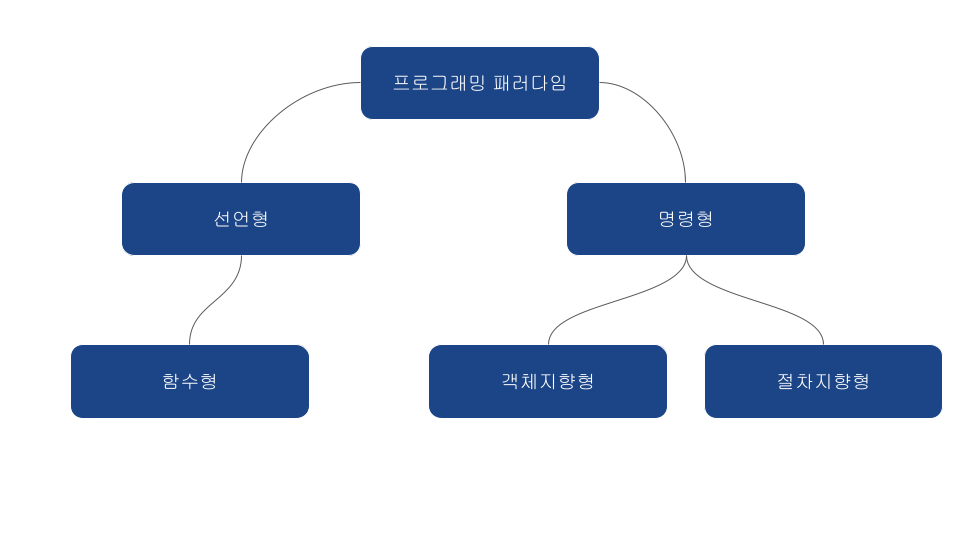
선언형과 함수형 프로그래밍
선언형 프로그래밍(declarartive programming)이란 ‘무엇을’ 풀어내는가에 집중하는 패러다임이며, “프로그램은 함수로 이루어진 것이다.”라는 명제가 담겨 있는 패러다임이기도 합니다. 함수형 프로그래밍(functional programming)은 선언형 패러다임의 일종입니다. 지금부터 함수형 프로그래밍에 대해 알아보겠습니다.
const arr = [1,2,3,4,5,10,11] .reduce((max, num) => num > max ? num : max, 0) console.log(ret) >>> 12위 코드에서 Array.prototype.reduce() 메서드는 배열만 받아서 누적한 결괏값을 반환하는 순수 함수입니다.
함수형 프로그래밍은 이와 같은 작은 ‘순수 함수’들을 블록처럼 쌓아 로직을 구현하고 ‘고차 함수’를 통해 재사용성을 높인 프로그래밍 패러다임입니다. 자바스크립트는 단순하고 유연한 언어이며, 함수가 일급 객체이기 때문에 객체지향 프로그래밍보다는 함수형 프로그래밍 방식이 선호됩니다.
순수 함수
출력이 입력에만 의존하는 것을 의미합니다.
function pure(a, b) { return a + b; } console.log(pure(2, 3)); // 5 console.log(pure(5, 3)); // 8 console.log(pure(10, 3)); // 13위의 코드는 두 개의 인자를 받아서 더한 값을 반환하는 간단한 함수입니다. 이 함수는 순수 함수입니다.
순수 함수란 입력값이 같으면 항상 같은 결과를 반환하면서 부작용(side effect)이 없는 함수를 의미합니다. 부작용이 없다는 것은 함수 내에서 함수 외부의 값에 영향을 미치지 않는다는 것을 의미합니다.
위의 pure 함수는 입력값에 대한 출력값이 항상 같으며, 함수 외부의 값을 변경하지 않기 때문에 순수 함수입니다. 순수 함수를 사용하면 코드의 예측 가능성이 높아지고, 디버깅이 쉬워지며, 병렬 처리 등 성능 향상 기법을 적용하기 쉬워집니다.
pure 함수는 들어오는 매개변수 a,b에만 영향을 받습니다. 만약 a,b 말고 다른 전역 변수 c 등이 출력에 영향을 주면 순수 함수가 아닙니다.
고차함수
고차 함수란 함수가 함수를 값처럼 매개변수로 받아 로직을 생성할 수 있는 것을 말합니다.
function multiplyBy(factor) { return function (num) { return num * factor; } } const double = multiplyBy(2); const triple = multiplyBy(3); console.log(double(5)); // 10 console.log(triple(5)); // 15위 코드에서 multiplyBy() 함수는 매개변수 factor를 받아서 함수를 반환합니다. 반환된 함수는 매개변수 num을 받아서 factor와 곱한 값을 반환합니다. 이렇게 함수를 반환하는 함수를 고차 함수라고 합니다.
위 코드에서 multiplyBy(2)를 호출하면 double이라는 함수가 반환됩니다. double 함수는 매개변수 num을 받아서 num * 2를 반환합니다. 마찬가지로 multiplyBy(3)을 호출하면 triple이라는 함수가 반환됩니다. triple 함수는 매개변수 num을 받아서 num * 3을 반환합니다.
이렇게 고차 함수를 사용하면 코드의 중복을 줄일 수 있고, 코드의 가독성을 높일 수 있습니다. 또한 함수를 인자로 받아서 로직을 생성하는 고차 함수는 함수형 프로그래밍에서 매우 중요한 역할을 합니다.
일급 객체
이때 고차 함수를 쓰기 위해서는 해당 언어가 일급 객체라는 특징을 가져야 하며 그 특징은 다음과 같습니다.
- 변수나 메서드에 함수를 할당할 수 있습니다
- 함수 안에 함수를 매개변수로 담을 수 있습니다
- 함수가 함수를 반환할 수 있습니다
객체지향 프로그래밍
객체지향 프로그래밍(OOP, Object-Oriented Programming)은 객체들의 집합으로 프로그램의 상호 작용을 표현하며 데이터를 객체로 취급하여 객체 내부에 선언된 메서드를 활용하는 방식을 말합니다. 설계에 많은 시간이 소요되며 처리 속도가 다른 프로그래밍 패러다임에 비해 상대적으로 느립니다.
class Animal { constructor(name, color) { this.name = name; this.color = color; } speak() { console.log(`${this.name} makes a noise.`); } } class Dog extends Animal { constructor(name, color, breed) { super(name, color); this.breed = breed; } speak() { console.log(`${this.name} barks.`); } } const dog = new Dog("Fido", "brown", "Golden Retriever"); dog.speak(); // "Fido barks."위 코드에서 Animal 클래스는 이름과 색을 가진 동물 객체를 생성하는 생성자와 동물이 소리를 내는 speak() 메서드를 가지고 있습니다.
Dog 클래스는 Animal 클래스를 상속하며, 이름, 색, 그리고 견종을 가진 개 객체를 생성하는 생성자와 개가 짖는 speak() 메소드를 가지고 있습니다. Dog 클래스에서 speak() 메소드를 재정의하여 Animal 클래스의 speak() 메소드를 덮어썼습니다.
객체지향 프로그래밍은 객체의 상태와 행동을 캡슐화하여 객체를 조직화하고 추상화하는 방식으로 프로그래밍을 하는 패러다임입니다.
객체들은 클래스라는 일종의 청사진을 기반으로 만들어지며, 클래스는 객체의 공통적인 속성과 행동을 정의합니다. 상속, 캡슐화, 다형성 등의 개념을 활용하여 유연하고 확장 가능한 코드를 작성할 수 있습니다.
추상화
추상화(abstraction)란 복잡한 시스템으로부터 핵심적인 개념 또는 기능을 간추려내는 것을 의미합니다. 예를 들어 강아지라는 객체가 있을 때, ‘다리가 4개’, ‘포유류’, ‘주인에게 충실하고 애정 어린 동물’, ‘멍멍 짖는 소리를 내는 동물’, ‘귀여움’, ‘털이 몸을 뒤덮음’과 같은 특징이 있을 수 있습니다. 이 중에서 제가 생각했을 때 필요한 강아지의 특징을 코드로 뽑아낼 때, 강아지의 일부 특징인 ‘다리가 4개’, ‘주인에게 충실하고 애정 어린 동물’, ‘귀여움’만 뽑아내거나 조금 더 간추려서 나타내는 것을 추상화라고 할 수 있습니다.
캡슐화
캡슐화(encapsulation)는 객체의 속성과 메서드를 하나로 묶고 일부를 외부에 감추어 은닉하는 것을 말합니다. 이는 객체의 내부 구조를 외부에서 직접적으로 접근하지 못하도록 하여 객체의 무결성을 보호하고, 객체와 객체 간의 결합도를 낮추어 유지보수성을 높이는 효과가 있습니다.
다음은 캡슐화를 구현한 예제 코드입니다.
class Person { #name; #age; constructor(name, age) { this.#name = name; this.#age = age; } get name() { return this.#name; } set name(name) { this.#name = name; } get age() { return this.#age; } set age(age) { this.#age = age; } sayHello() { console.log(`Hello, my name is ${this.#name} and I am ${this.#age} years old.`); } } const person = new Person("John", 30); person.sayHello(); // "Hello, my name is John and I am 30 years old." console.log(person.name); // "John" person.name = "Jane"; console.log(person.name); // "Jane"위 코드에서 Person 클래스는 name과 age라는 두 개의 속성을 가지고 있습니다. 이 두 속성은 # 기호로 시작되어서 private 속성으로 만들어져 있습니다. 이렇게 private 속성을 만들면 외부에서 직접적으로 접근할 수 없기 때문에 캡슐화를 구현한 효과가 있습니다.
이 클래스는 get과 set으로 구성된 getter와 setter 메서드를 가지고 있습니다. get 메서드는 private 속성에 접근하여 값을 반환하고, set 메서드는 private 속성에 값을 할당합니다. 이렇게 getter와 setter를 사용하면 외부에서 private 속성에 접근하지 못하도록 하면서도 속성 값을 변경하거나 가져올 수 있습니다.
마지막으로 sayHello 메서드는 name과 age 속성을 출력하는 메서드입니다. 이 메서드는 private 속성에 직접 접근하지 않고, getter를 통해 값을 가져와서 출력합니다.
이렇게 private 속성과 getter, setter를 사용하여 캡슐화를 구현하면 객체의 내부 구조를 감추어 외부에서 직접적인 접근을 막으면서도, 객체의 속성 값을 변경하거나 가져오는 등의 작업을 할 수 있습니다.
상속성
상속성(inheritance)은 상위 클래스의 특성을 하위 클래스가 이어받아서 재사용하거나 추가, 확장하는 것을 말합니다. 코드의 재사용 측면, 계층적인 관계 생성, 유지 보수성 측면에서 중요합니다.
객체지향 프로그래밍에서 상속성은 상위 클래스의 특성을 하위 클래스가 이어받아서 재사용하거나 추가, 확장하는 것을 말합니다. 이를 통해 코드의 재사용성을 높일 수 있습니다.
다음은 자바스크립트에서 상속성을 구현한 예제 코드입니다.
class Animal { constructor(name, color) { this.name = name; this.color = color; } speak() { console.log(`${this.name} makes a noise.`); } } class Dog extends Animal { constructor(name, color, breed) { super(name, color); this.breed = breed; } speak() { console.log(`${this.name} barks.`); } } const dog = new Dog("Fido", "brown", "Golden Retriever"); dog.speak(); // "Fido barks."위 코드에서 Animal 클래스는 이름과 색을 가진 동물 객체를 생성하는 생성자와 동물이 소리를 내는 speak() 메서드를 가지고 있습니다.
Dog 클래스는 Animal 클래스를 상속하며, 이름, 색, 그리고 견종을 가진 개 객체를 생성하는 생성자와 개가 짖는 speak() 메소드를 가지고 있습니다. Dog 클래스에서 speak() 메소드를 재정의하여 Animal 클래스의 speak() 메소드를 덮어썼습니다.
이렇게 상속성을 이용하면 공통된 특성을 가진 클래스를 부모 클래스로 만들고, 이를 상속받아 자식 클래스에서 추가적인 기능을 구현할 수 있습니다. 이러한 구조는 코드의 재사용성을 높일 뿐만 아니라 유지보수성을 향상하는 효과가 있습니다.
다형성
다형성(polymorphism)은 하나의 메서드나 클래스가 다양한 방법을 동작하는 것을 말합니다. 대표적으로 오버로딩, 오버라이딩이 있습니다.
오버로딩
오버로딩(overloading)은 같은 이름을 가진 메서드를 여러 개 두는 것을 말합니다. 메서드의 타입, 매개변수의 유형, 개수 등으로 여러 개를 둘 수 있으며 컴파일 중에 발생하는 ‘정적’ 다형성입니다.
public class OverloadExample { public static void main(String[] args) { OverloadExample example = new OverloadExample(); System.out.println(example.addition(1, 2)); System.out.println(example.addition(1, 2, 3)); System.out.println(example.addition(1.0, 2.0)); } public int addition(int a, int b) { return a + b; } public int addition(int a, int b, int c) { return a + b + c; } public double addition(double a, double b) { return a + b; } }위 코드는 오버로딩의 예시입니다. OverloadExample 클래스에는 addition 메서드가 있습니다. 이 메서드는 이름은 같지만 매개변수의 수와 타입이 다른 세 가지 버전이 있습니다.
addition 메서드는 정수형 두 개, 정수형 세 개, 실수형 두 개를 더한 값을 반환합니다. 이때, 각각의 메서드는 이름이 같기 때문에 구분이 가능한 매개변수를 가지고 있습니다.
오버로딩은 컴파일러가 메서드를 호출할 때, 매개변수의 수와 타입을 바탕으로 어떤 메서드를 호출할지 결정합니다. 이를 통해 메서드의 이름을 일관성 있게 유지하면서도 다양한 매개변수 조합을 처리할 수 있습니다.
오버라이딩
오버라이딩(overriding)은 주로 메서드 오버라이딩(method overriding)을 말하며 상위 클래스로부터 상속받은 메서드를 하위 클래스가 재정의하는 것을 의미합니다.
이는 런타임 중에 발생하는 ‘동적’ 다형성입니다.
class Animal { public void speak() { System.out.println("Animal speaks"); } } class Dog extends Animal { @Override public void speak() { System.out.println("Dog barks"); } } public class Main { public static void main(String[] args) { Animal animal = new Animal(); animal.speak(); // "Animal speaks" Dog dog = new Dog(); dog.speak(); // "Dog barks" } }위 코드에서 Animal 클래스는 speak() 메서드를 가지고 있습니다. 이 클래스를 상속받은 Dog 클래스에서는 speak() 메서드를 재정의(오버라이딩)하여 자신의 동작을 구현합니다.
Dog 클래스에서는 @Override 어노테이션을 사용하여 speak() 메서드가 오버라이딩 되었다는 것을 명시합니다. 이를 통해 컴파일러는 상위 클래스의 메서드를 오버라이딩한 메서드를 찾아내어 런타임에 동적으로 호출할 수 있습니다.
오버라이딩을 사용하면 상위 클래스에서 정의된 메서드를 하위 클래스에서 필요에 따라 재정의하여 사용할 수 있습니다. 이는 하위 클래스에서 상위 클래스의 기능을 확장하거나 변경할 때 유용합니다.
OOP 설계 원칙
객체지향 프로그래밍을 설계할 때는 SOLID 원칙을 지켜줘야 합니다. S는 단일 책임 원칙, O는 개방-폐쇄 원칙, L은 리스코프 치환 원칙, I는 인터페이스 분리 원칙, D는 의존성 역전 원칙을 의미합니다.
단일 책임 원칙
단일 책임 원칙(SRP, Single Responsibility Principle)은 모든 클래스는 각각 하나의 책임만 가져야 하는 원칙입니다. 예를 들어 A라는 로직이 존재한다면 어떠한 클래스는 A에 관한 클래스여야 하고 이를 수정한다고 했을 때도 A와 관련된 수정이어야 합니다.
다음은 단일 책임 원칙을 지키지 않은 예시 코드입니다.
class Employee { private String name; private int age; public Employee(String name, int age) { this.name = name; this.age = age; } public void save() { // save employee to database } public void print() { // print employee details } public void sendEmail() { // send email to employee } }위 코드에서 Employee 클래스는 직원 정보를 저장하고, 출력하고, 이메일을 보내는 기능을 모두 가지고 있습니다. 이러한 구조는 단일 책임 원칙을 위반하며, 유지보수성이 낮아지고, 코드가 복잡해지게 됩니다.
다음은 단일 책임 원칙을 지킨 예시 코드입니다.
class Employee { private String name; private int age; public Employee(String name, int age) { this.name = name; this.age = age; } public void save() { // save employee to database } public void print() { // print employee details } } class EmailSender { public void sendEmail(Employee employee) { // send email to employee } }위 코드에서 Employee 클래스는 직원 정보를 저장하고, 출력하는 역할만 가지고 있습니다. EmailSender 클래스는 Employee 객체를 받아서 이메일을 보내는 역할만 수행합니다. 이를 통해 각 클래스는 하나의 책임만 가지고 있으며, 유지보수성이 향상되고 코드가 간결해집니다.
개방-폐쇄 원칙
개방-폐쇄 원칙(OCP, Open Closed Principle)은 유지 보수 사항이 생긴다면 코드를 쉽게 확장할 수 있도록 하고 수정할 때는 닫혀 있어야 하는 원칙입니다. 즉, 기존의 코드는 잘 변경하지 않으면서도 확장은 쉽게 할 수 있어야 합니다.
다음은 개방-폐쇄 원칙(OCP)을 지키는 예시 코드입니다.
interface Shape { double area(); } class Rectangle implements Shape { private double width; private double height; public Rectangle(double width, double height) { this.width = width; this.height = height; } public double area() { return width * height; } } class Circle implements Shape { private double radius; public Circle(double radius) { this.radius = radius; } public double area() { return Math.PI * radius * radius; } } class AreaCalculator { public double calculateArea(Shape[] shapes) { double totalArea = 0; for (Shape shape : shapes) { totalArea += shape.area(); } return totalArea; } }위 코드에서 Shape 인터페이스는 도형의 면적을 계산하는 area() 메서드를 가지고 있습니다. Rectangle 클래스와 Circle 클래스는 Shape 인터페이스를 구현하여 각각 직사각형과 원의 면적을 계산할 수 있습니다.
AreaCalculator 클래스는 Shape 인터페이스를 구현하는 클래스의 객체 배열을 받아서 모든 도형의 면적을 합산하여 반환하는 calculateArea() 메서드를 가지고 있습니다.
이러한 구조를 통해 새로운 도형 클래스가 추가되더라도 AreaCalculator 클래스는 변경할 필요가 없습니다. 새로운 도형 클래스는 Shape 인터페이스를 구현하기만 하면 되며, AreaCalculator 클래스는 이를 고려하여 작성되었기 때문입니다. 이는 개방-폐쇄 원칙을 지키는 예시입니다.
리스코프 치환 원칙
리스코프 치환 원칙(LSP, Liskov Substitution Principle)은 프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 하는 것을 의미합니다. 클래스는 상속이 되기 마련이고 부모, 자식이라는 계층 관계가 만들어집니다. 이때 부모 객체에 자식 객체를 넣어도 시스템이 문제없이 돌아가게 만드는 것을 말합니다.
다음은 리스코프 치환 원칙을 지키지 않은 예시 코드입니다.
class Rectangle { protected int width; protected int height; public Rectangle(int width, int height) { this.width = width; this.height = height; } public int getArea() { return width * height; } } class Square extends Rectangle { public Square(int sideLength) { super(sideLength, sideLength); } public void setWidth(int width) { this.width = width; this.height = width; } public void setHeight(int height) { this.width = height; this.height = height; } } public class Main { public static void main(String[] args) { Rectangle rectangle = new Square(5); rectangle.setWidth(10); rectangle.setHeight(20); System.out.println(rectangle.getArea()); // 400 } }위 코드에서 Rectangle 클래스는 가로와 세로 길이를 가지고 면적을 계산하는 getArea() 메서드를 가지고 있습니다.
Square 클래스는 Rectangle 클래스를 상속받아 정사각형의 면적을 계산하는 클래스입니다. Square 클래스에서는 가로와 세로 길이를 동시에 바꾸도록 setWidth()와 setHeight() 메서드를 재정의하였습니다.
위 코드에서 Square 객체를 생성하여 Rectangle 타입으로 참조하고 있습니다. 이때, Rectangle 객체의 가로와 세로 길이를 각각 10과 20으로 설정하고 면적을 계산하면 200이 아닌 400이 나오게 됩니다. 이러한 결과는 리스코프 치환 원칙을 위반하며, Square 클래스가 Rectangle 클래스의 하위 타입으로 적절하지 않다는 것을 의미합니다.
다음은 리스코프 치환 원칙을 지키는 예시 코드입니다.
interface Shape { int getArea(); } class Rectangle implements Shape { protected int width; protected int height; public Rectangle(int width, int height) { this.width = width; this.height = height; } public int getArea() { return width * height; } } class Square implements Shape { private int sideLength; public Square(int sideLength) { this.sideLength = sideLength; } public int getArea() { return sideLength * sideLength; } } public class Main { public static void main(String[] args) { Shape rectangle = new Rectangle(10, 20); System.out.println(rectangle.getArea()); // 200 Shape square = new Square(5); System.out.println(square.getArea()); // 25 } }위 코드에서 Shape 인터페이스를 사용하여 Rectangle 클래스와 Square 클래스가 하나의 타입으로 취급되도록 합니다. Rectangle 클래스와 Square 클래스는 각각 Shape 인터페이스를 구현하여 getArea() 메서드를 가지고 있습니다.
이러한 구조를 통해 Rectangle 클래스와 Square 클래스는 각각 다른 면적을 계산하지만, 하나의 타입으로 취급될 수 있습니다. 이는 리스코프 치환 원칙을 지키는 예시입니다.
인터페이스 분리 원칙
인터페이스 분리 원칙(ISP, Interface Segregation Principle)은 하나의 일반적인 인터페이스보다 구체적인 여러 개의 인터페이스르 만들어야 하는 원칙을 말합니다.
다음은 인터페이스 분리 원칙을 지키지 않은 예시 코드입니다.
interface Machine { void print(); void fax(); void scan(); } class AllInOnePrinter implements Machine { public void print() { // print something } public void fax() { // send fax } public void scan() { // scan something } }위 코드에서 Machine 인터페이스는 프린트, 팩스, 스캔 기능을 가지고 있습니다. AllInOnePrinter 클래스는 Machine 인터페이스를 구현하여 프린트, 팩스, 스캔 기능을 모두 가지고 있습니다.
이러한 구조는 인터페이스 분리 원칙을 위반하며, AllInOnePrinter 클래스가 스캔 기능을 필요로 하지 않을 때도 Machine 인터페이스의 모든 메서드를 구현해야 한다는 문제가 있습니다.
다음은 인터페이스 분리 원칙을 지킨 예시 코드입니다.
interface Printer { void print(); } interface Scanner { void scan(); } interface Fax { void fax(); } class AllInOnePrinter implements Printer, Scanner, Fax { public void print() { // print something } public void scan() { // scan something } public void fax() { // send fax } }위 코드에서 Printer, Scanner, Fax 인터페이스는 각각 프린트, 스캔, 팩스 기능을 가지고 있습니다. AllInOnePrinter 클래스는 이 세 개의 인터페이스를 구현하여 프린트, 스캔, 팩스 기능을 모두 가지고 있습니다.
이러한 구조를 통해 AllInOnePrinter 클래스는 필요한 기능만 구현할 수 있으며, 인터페이스 분리 원칙을 지키게 됩니다.
의존 역전 원칙
의존 역전 원칙(DIP, Dependency Inversion Principle)은 자신보다 변하기 쉬운 것에 의존하던 것을 추상화된 인터페이스나 상위 클래스를 두어 변하기 쉬운 것의 변화에 영향받지 않게 하는 원칙을 말합니다.
예를 들어 타이어를 갈아 끼울 수 있는 틀을 만들어 놓은 후 다양한 타이어를 교체할 수 있어야 합니다. 즉, 상위 계층은 하위 계층의 변화에 대한 구현으로부터 독립해야 합니다.
이를 자바 코드로 나타내면 다음과 같습니다.
interface Engine { void start(); } class GasolineEngine implements Engine { public void start() { // start the gasoline engine } } class ElectricEngine implements Engine { public void start() { // start the electric engine } } class Car { private Engine engine; public Car(Engine engine) { this.engine = engine; } public void start() { engine.start(); } }위 코드에서 Engine 인터페이스는 엔진을 시작하는 start() 메서드를 가지고 있습니다. GasolineEngine 클래스와 ElectricEngine 클래스는 Engine 인터페이스를 구현하여 각각 가솔린 엔진과 전기 엔진을 시작할 수 있습니다.
Car 클래스는 Engine 인터페이스를 구현하는 객체를 생성자로 받아들이고, start() 메서드를 호출할 때 이 객체의 start() 메서드를 실행합니다. 이러한 구조를 통해 Car 클래스는 자신이 어떤 종류의 엔진을 사용하더라도 Engine 인터페이스를 구현하는 객체만을 사용하며, 엔진의 종류 변화에 대한 영향을 받지 않습니다. 이는 의존 역전 원칙을 지키는 예시입니다.
절차지향형 프로그래밍
절차지향형 프로그래밍은 로직이 수행되어야 할 연속적인 계산 과정으로 이루어져 있습니다. 일이 진행되는 방식으로 그저 코드를 구현하기만 하면 되기 때문에 코드의 가독성이 좋으며 실행 속도가 빠릅니다. 그렇기 때문에 계산이 많은 작업 등에 쓰입니다.
다음은 절차형 프로그래밍의 예시 코드입니다.
public class Main { public static void main(String[] args) { int[] numbers = {5, 3, 2, 6, 1, 4}; int sum = 0; for (int i = 0; i < numbers.length; i++) { sum += numbers[i]; } System.out.println("합계: " + sum); int max = numbers[0]; for (int i = 1; i < numbers.length; i++) { if (numbers[i] > max) { max = numbers[i]; } } System.out.println("최댓값: " + max); } }위 코드는 배열의 합계와 최댓값을 구하는 예시입니다. 각각의 로직은 순차적으로 실행되며, 변수의 값을 변경하면서 계산이 이루어집니다. 이는 절차형 프로그래밍의 대표적인 예시입니다.
// 자바스크립트 let numbers = [5, 3, 2, 6, 1, 4]; let sum = 0; for (let i = 0; i < numbers.length; i++) { sum += numbers[i]; } console.log("Sum: " + sum); let max = numbers[0]; for (let i = 1; i < numbers.length; i++) { if (numbers[i] > max) { max = numbers[i]; } } console.log("Max: " + max);패러다임의 혼합
여러 가지의 프로그래밍 패러다임을 알아보았습니다. 그렇다면 어떠한 패러다임이 가장 좋을까요? 답은 “그런 것은 없다.”라는 것입니다. 비즈니스 로직이나 서비스의 특징을 고려해서 패러다임을 정하는 것이 좋습니다. 하나의 패러다임을 기반으로 통일하여 서비스를 구축하는 것도 좋은 생각이지만 여러 패러다임을 조합하여 상황과 맥락에 따라 패러다임 간의 장점만 취해 개발하는 것이 좋습니다.
예를 들어, 데이터베이스나 머신 러닝 파이프라인과 같은 복잡한 시스템을 구축해야 한다면 객체지향 프로그래밍이 유리할 수 있습니다. 객체지향 프로그래밍은 코드의 모듈화와 재사용성을 높일 수 있기 때문입니다.
반면에, 이벤트 기반의 시스템이 필요하다면 함수형 프로그래밍이 적합합니다. 함수형 프로그래밍은 상태 변경을 줄이고 복잡한 시스템을 간단하게 구현할 수 있습니다.
절차지향 프로그래밍은 C 언어와 같은 하드웨어 제어나 계산이 많은 작업에서 사용됩니다.
또한, 패러다임을 혼합해서 사용하는 것도 좋은 방법입니다. 예를 들어 백엔드에서는 객체지향 프로그래밍을 사용하면서, 프론트엔드에서는 함수형 프로그래밍을 사용하는 것이 좋습니다.
따라서, 프로그래밍 패러다임을 선택할 때는 해당 서비스나 비즈니스 로직의 특징을 고려하고, 필요한 경우 패러다임을 혼합해서 사용하는 것이 좋습니다.
예제 코드에 대하여 🤖
모든 예제 코드는 notion AI를 통해 작성되었습니다. 예전에는 IDE를 통해 직접 작업해서 코드를 복붙 했었는데, AI로 인해 글을 쓸 때 드는 비용이 매우 매우 낮아지는 것 같아요. 단순히 정보만 전달하는 것보다 예제코드를 첨부하면서 이해하기 쉬운 것도 제가 글 쓰면서도 매우 도움이 되는 부분이라고 생각합니다.
'Computer Science' 카테고리의 다른 글
운영체제 (1) 2024.04.25 네트워크 (2) (1) 2024.04.19 네트워크 (1) (1) 2024.04.18 기본 리눅스 명령어 15가지 알아두기 (1) 2024.02.26 - 선언형과 함수형 프로그래밍